
Good journalists file clean copy. But what does that mean? This article gives journalists the basics they need to know to ensure that every character, word, sentence, and paragraph they intended to write gets correctly saved and reproduced on computer systems, and ultimately online and in print. You’ll learn enough to avoid the dreaded borked Unicode.
Clean copy is an established concept in print journalism. Conservatively, the term refers to text that is spelled and punctuated correctly and makes sense. As an editor who was formative in my development, the late Sid Adilman of the Toronto Star, put it, the goal is to write an article that “reads well.” Clean copy is a prerequisite for that.
But I want to expand the definition to encompass character encoding. Your copy can’t be considered “clean” unless and until it is stored and reproduced correctly. Getting character encoding right is an absolute necessity for working print journalists, which is all well and good except for the fact that nobody has ever bothered to teach journalists what character encoding is.
By the time you’re done reading this article, you’ll gain knowledge of character encoding that leads to confidence that you can write clean copy and muscle memory and good habits to actually do it.
The concepts involved in producing clean copy can extend way out to the horizon, but journalists don’t need to worry about expert-level details. Here is the complete list of facts you need to know.
Computers store characters as numbers. That includes visible characters like letters and numerals; whitespace characters like spaces and tabs; and invisible characters like optional hyphens. At root, they’re all numbers. A system of enumeration of characters is called character encoding.
In the past, there were dozens of conflicting sets of numbers used to enumerate characters. Those have all been superseded by a single numbering system, Unicode.
Unicode does not include every conceivable character, but every character you the journalist will need is available in Unicode. Corollary: There is no such thing as a “special character.” (Really, there isn’t.)
To write clean copy, everything you write, edit, pass on to someone else, receive from someone else, and publish has to use Unicode from start to finish.
Unicode is a large specification that can be expressed in a variety of ways, but in the normal course of events the only variation you need to know about is UTF‑8. You don’t even have to know what that stands for.
In essentially every case, you just type, insert, or paste the actual character you want – just as with characters you find noncontroversial. In rare cases, you will refer to characters by their Unicode number. (That’s called using a character entity or escaping a character.)
There. Now you’re up to speed. For the working hack, it really is that simple.
The most important advice is the easiest: Just type the character you want. You may need to learn how to type it, but I’m going to teach you how. You may need to copy and paste it from another source. But the point is use the character you want right in your document. And do that everywhere – hed, dek, body copy, in RSS, on Twitter.
There are rare exceptions to this rule. When the character your system displays can be confused with something else or is simply invisible, as in the case of whitespace or non-breaking hyphen (see below), you need to enter a character entity, which uses a sequence of other characters to escape the character you actually want. In these cases, you’re specifying the character by an agreed-upon name or by its Unicode number. You do that by starting the name or number with an ampersand and ending it with a semicolon. Some examples, purely for illustration purposes:
& for ampersand &é for éà or à for àYou have to know this troublesome implementation detail because it is the only way to reliably enter and edit the few characters that demand this approach. Absolutely do not use this method to enter what you think are “special characters” in the day-to-day run of your work as writer or editor.
I want to make sure you know what I’m talking about, so I’m going to show you a few errors of character encoding. After you finish this article, you will be in a position to avoid borked Unicode like this for the rest of your career.
A mismatch in server and browser settings means the browser can’t figure out the character encoding and uses the wrong characters.

Characters are saved as numerical references instead of the actual character, but that process goes wrong.
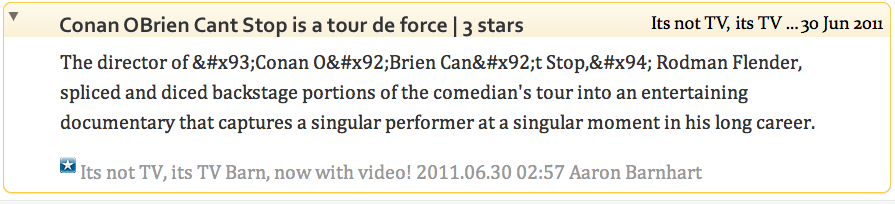
The character may exist in the file, but it’s so badly encoded the browser can’t even guess what it is. (The question mark in a diamond is a character from the Apple Last Resort font. It’s widely seen in this scenario but it isn’t any kind of “standard.”)

Accented characters just disappear.

Smart quotes never live up to their name and simply go crazy.

In the English language, the giveaway character that can conclusively prove your copy is dirty is this: ‘ (opening single quotation mark). Why?
If it’s missing or replaced by ' (neutral apostrophe), that means someone can’t type the character or thinks downstream systems can’t accept it, or those downstream systems changed it behind your back.
If it’s replaced by apostrophe (’), it means someone relied on so-called smart quotes and didn’t double-check for errors.
If it’s used where it shouldn’t be – a common occurrence, as in rock ‘n’ roll or ‘90s grunge rock – it means someone didn’t know the difference or (again) foolishly trusted smart quotes.
If you can’t get opening single quotation mark right, you probably can’t get anything right that isn’t a nice easy letter or a number.
You can bang out copy in Microsoft Word if you want. With modern versions of MS Word, that copy will always use Unicode. Problem solved? No, because Word is borderline useless when it comes to fixing someone else’s copy.
At a minimum, you need to be able to do all of the following:
Save and reopen files of unknown or incorrect encoding. (Goal: Always yield UTF‑8 plain text or markup like HTML. Never yield word-processing formats like .doc and RTF.)
Remove carriage returns from inside paragraphs and other places.
Reliably change neutral quotes to correct quotes (including when nested).
Reliably change any of the countless incorrect analogues of en and em dashes to the real thing.
Escape the rare characters that need them.
You can gin up macros to do most of these things in MS Word, but you have better things to do.
Maybe you associate writing on a computer with “word processing,” and associate word processing with the market leader, MS Word. But here I am strongly recommending you update your workflow to use a real text editor. You may not even know this category of software exists, but it does, and it is mature and can do everything you need.
Windows options: You shouldn’t be using Windows to edit clean copy. If you have no choice, consider Notepad++; Sublime Text; Dreamweaver. (Absolutely not the built-in Notepad utility, not even for emergency usage; it accepts Unicode handily but is too underpowered and inconvenient.)
Unreadable onscreen type leads to copy errors. Always use nice big fonts (16 pixels minimum in typical cases), and unless you know you need to, don’t use monospaced fonts, especially not Courier.
Neutral versions of either of those (' and ") do not cut it anywhere, at any time, outside of programming and markup.
When consecutive quotes follow each other, or when an apostrophe sits inside a quotation mark, you have to use at least a thin space to separate them, as described below.
By consensus, we don’t have to write foreign words in their own script if it isn’t Latin script. We don’t have to write Москва for Moscow and 日本 for Japan. Foreign proper nouns with accepted English spellings, like Cologne (for Köln, Germany), don’t have to be changed.
But one source of unclean copy is the belief that a word that contains accents or diacritics is weird and foreign and that the accents are optional. Wrong. Accents or diacritics are intrinsic to correct spelling. Just as cant and wont are words that differ from can’t and won’t, resume and résumé are two different words.
In case I’m not making myself clear, leaving out accents means you’ve misspelled the word.
To write clean copy, you have to know what accents are called. You can’t use fake French names for accents; all of them already have English names. You cannot use vague, impressionistic, guaranteed-to-be-misunderstood descriptors like “the one that goes from left to right.”
Why learn the right terminology? You can’t work in ignorance, first of all, but more importantly, you have to be able to correct someone’s copy, or instruct someone on how to enter text correctly, over the phone, in person, or via chat – anywhere you can’t actually draw a character on a printout. (“No, the first letter is cap E acute. You sent me grave accent. Fix it.”)
Important single letters from other languages:
(I’ve grouped these letters for convenience. None of these four languages uses all of them.)
That isn’t the full list of diacritics or letters, but the point is you must be able to name these letters and accents on sight, cold, without a cheatsheet. Do you think they’ll never come up in the copy you write? Well, maybe they won’t, but they’ll come up in copy you read and possibly in copy you edit.
What if the Icelandic banking system collapses? Who won the Turkish election?
If you’re an arts writer and think this sort of thing is never going to come up because it’s “too technical,” well, don’t half your friends work at Condé Nast? Then again, they can’t get that name right either:

And I assume you’ll someday have to name-drop the family of actors named Skarsgård, or review popular mystery writers like Jo Nesbø and Arnaldur Indriðason, or write a thinkpiece about cinéma vérité or causes célèbres.
And tell me: What kind of restaurant critic can’t spell chèvre?
The idea that accents are not really an integral and mandatory component of good copy – it’s just so passé.
You need to know when to use and how to enter an en dash (between these letters: a–b) and an em dash (between these letters: a—b).
Style guides may insist you use an em dash not surrounded by spaces, but that usage does not work online (browsers break lines unpredictably) and barely works in print. Use space-endash-space by preference.
Typewriter-style fake em dashes -- (two hyphens possibly surrounded by spaces) have to be converted. Don’t ever use hyphen-hyphen as a claimed em dash. First of all, it isn’t, and second of all, some system will surely come along and break a line between the dashes.
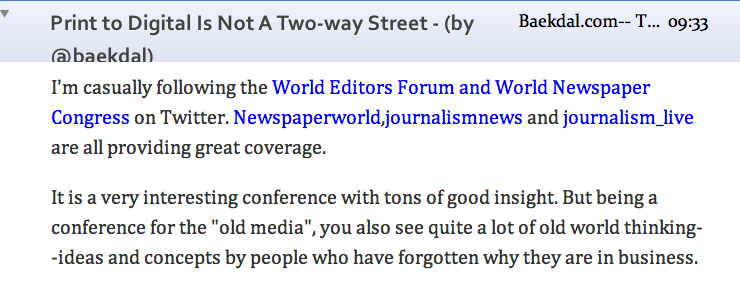
Space-hyphen-space is not an em dash and needs to be converted.
You have to manually inspect copy for en dashes errantly replaced by hyphen. I’m talking about copy that might have been correct in the original but was dumbed down for the Web by someone or some system who didn’t understand Unicode – e.g., converting New York–style pizza to New York-style pizza or New-York-style pizza.
Non-breaking hyphen is available and should be used, especially in small alphanumeric sequences (IRS W‑8B form) or in words that begin or end with a hyphen (left‑ and right-hand drive; free-speech and ‑assembly rights). As with whitespace (see below), you need to escape the character – enter it as ‑.
Your system may mis-encode the regular visible hyphen any number of ways, including as a non-breaking hyphen that is immediately followed by a displayed optional hyphen or as two hyphens.

The standard wordspace (what you get when you press the spacebar on your computer) is noncontroversial in the hack context.
Among the many available whitespace characters:
These space characters are tricky enough that you should use character entities for them. Why? So you can identify them with certainty in source code. Two normal wordspaces look a lot like an em space. Of course no one writes two consecutive spaces in normal English prose, but HTML source code and many other contexts permit two consecutive wordspaces, collapsing them to a single wordspace. To tell those apart from an intended em or en space, use a character entity for them.
For regular Web pages, just use   and   for em and en space. Thin space is, not surprisingly;  . Non-breaking space is .
Dozens of arrow characters exist in Unicode and you should never use sequences of punctuation in their place. To show four of many options:
Many commonly-used fractions are available as predefined Unicode characters. There is no reason to write something like 3 1/4 ever again. (Also inadvisable because, somewhere along the way, a line will break between the integer and the fraction.)
Do not try to fake subscript or superscript numerals by using smaller font sizes. Also don’t give up and just write a normal number inside parentheses or brackets. Use the actual Unicode numerals:
Subscript: ₀₁₂₃₄₅₆₇₈₉
Superscript: ⁰¹²³⁴⁵⁶⁷⁸⁹
Superscribed and subscribed letters and other characters are barely available in Unicode. This is another way of saying you can rely only on sub/super numerals, not letters or anything else.
It shouldn’t surprise you that basic symbols exist in Unicode. As with arrows, you shouldn’t use other characters to fake them.
Currency: $, £, and ¢ are easy ones, but nearly 20 years after the introduction of the euro (not “Euro”), hacks still write currency values like “20.99 euros” instead of using the available € symbol (€20.99).
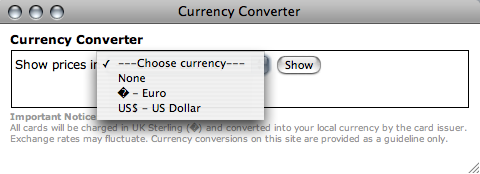
Legal: ©, ®, and ™ but not (C), (R), and (TM); servicemark ℠ and music publishing ℗ are available. ¶ and § can and should be used instead of “para.” and “s” or “S.”: ¶2, ¶¶7–8, §A2, §§1–3.
Heart: I♥NY as much as anybody, but I do not [heart] it or <3 it.
Math: The letter eks is not a multiplication sign; × is. (Hence no one buys a stack of “2x4s” at the lumber yard.) An opinion poll may be valid ±3 points 19 times out of 20, but it isn’t valid “+/‑” 3 points.
And at the very least use an en dash for a minus sign in reporting temperatures and other figures. (We can discuss the vagaries of Unicode in this regard some other time.)
You can easily find guides on the Web about typing “special characters.” These won’t help you at all. True, you do need to learn the technical basics about how to enter a character that isn’t printed on your keyboard. But what all those online guides don’t tell you is you need to develop muscle memory and habits.
If you can touch-type, you need to be able to touch-type common characters like accents and dashes. You can’t stop to think about it; that’s the kind of barrier that makes people think “To hell with it!” and just enter an incorrect substitute character.
When typing isn’t an option, you have to develop reliable ways of solving the problem, which can be as simple as Googling the character and copying and pasting.
To form muscle memory and habits, you need practice, practice, practice. The way to do this is to write a lot of copy using characters that aren’t simple letters and numbers. Don’t do that often? Then put some time into your professional development and carry out exercises like these.
Print out, or just set up in a separate window, easy text that uses accents, like Wikipedia’s lists of foreign-language terms used in English (e.g., from French, from German). Sit down and retype a few dozen of the entries.
Look up any common concept or noun (water, sky, calcium, life, baby) at Wikipedia, pick a translation in the target language of your choice, and retype a few paragraphs.
Take some well-edited copy from a print publication (e.g., a popular U.S. consumer magazine like Vanity Fair or GQ) and retype a few paragraphs. (For advanced learners, try duplicating the New Yorker’s idiosyncratic style.)
At all times use correct quotation marks and em and en dashes even if not in the original (a skill to develop in itself). These exercises will begin the process of instilling the muscle memory of typing the right characters.
If you aren’t a ten-finger touch-typist, do the same exercises. Even if you hunt and peck, you have your own muscle memory to develop.
Excluding speech recognition and other edge cases, you have three options for entering any character.
Look it up and paste it. This is by far the best option for the first time a document needs a truly rare character. But even in an age where we Google everything, this just never occurs to working hacks. Google the character you’re looking for and copy and paste it into your copy. (Now you see why you need to know what characters are called.) You then have the character at the ready for further copying and pasting. (Use Paste Special to paste as unformatted text in Microsoft Word or equivalent.)
Use a character picker. InDesign, Microsoft Word, Mac OS X, and countless other software “boasts” graphical character maps you can use to “easily” insert “special” characters. In practice they are phenomenally difficult and cumbersome to use and require near-expert knowledge just to figure out which category to look in. Use as a last resort.
And here’s how you absolutely are not going to enter a character:
On Windows, look up a number for a character and type it while holding down Alt, or type that number and then press Alt-X. Online guides tell you this is the only way to enter “special” characters. They’re wrong and they’re missing the point. It’s not that the numerical method is the only method, it’s the worst method. (Could you enter a full sentence of French text that way?)
Use “smart quotes.” Decades on, so-called smart quotes simply cannot handle English usage. It is smart quotes that cause the typical opening-single-quote errors mentioned before (rock ‘n’ roll, ‘90s). Even typographers make this mistake:

Systems cannot handle consecutive quotation marks (as in quotes within quotes). Smart quotes cannot disentangle typical British usage, which presents many structural ambiguities (opening single quote or apostrophe? closing single quote or apostrophe?). Advanced hacks, who are rare, can overcome the failings of smart quotes. Everyone else falls prey to them, and the victims are readers.
Typically but not universally, print publications are all-Mac shops. Online publications, and freelancers and independent bloggers, very often use Macs.
These people have nothing to worry about. It is dead simple to write, save, and transmit clean copy on Macs. Important keystrokes on Mac have not changed since the introduction of the Macintosh in 1984 and it is readily possible for a ten-finger typist to touch-type them.
The problem here is Windows. You need to have a lot of Unicode knowledge even to debate the issue, but just take my word for it on two counts here, and accept that I am not saying this just because I am a Macintosh supremacist.
One explanation for why you see so many incorrect characters online is simple: The writers are on Windows, and even if they know the right character, they pretty much can’t figure out how to.
So: This is not a time for platform equivalency. Use of Microsoft Windows prevents people from producing clean copy in the real world. Hence they over-rely on smart quotes, but that just means the system beats you up twice – once in your inability to type a character, once more when the computer guesses wrong.
There is a reasonable fix for professional writers using Windows: Turn on the U.S. International keyboard layout. Do that and all of a sudden you have the equivalent of a Mac keyboard layout and nearly everything just works. (More details.)
When somebody hands you copy, you need to do all the following to ensure it is clean:
Change all tab characters to space characters. Don’t just delete them, because they could be separating other characters or words and you don’t want to destroy that separation. Replace one tab character (^t in MS Word, \t in BBEdit) with one space.
Remove all soft-hyphen characters, especially word-initial soft hyphens used as a command not to hyphenate that word. These exported characters simply aren’t handled well by browsers. Soft hyphens exported by software like InDesign or newspaper composition systems like Harris or Atex will use the wrong character.
Soft hyphen displayed as ¬:

Soft hyphens erratically replaced by space or hyphen:

To make this work, export a test document known to have soft hyphens. Open that document in your text editor. Find the soft-hyphen character and save it in a document you can find later. Replace that character with nothing. Do the same with all your files from now on.
Any number of fake soft-hyphen characters are possible; you have to test your own system first to know which one it uses. Ideally your system would just stop outputting soft hyphens, but let’s be realistic.
If for some reason you want to add soft hyphens later, do so at that later stage. I strongly discourage this practice because it is the rendering engine (whatever sets the type in the final stage before a reader sees it) that should insert soft hyphens. Manually-inserted soft hyphens should be reserved for intentional fine control, not as a task you apply to every line of text.
Check every non-breaking space to ensure it really has to be there. Systems include for a variety of spurious reasons, and your copy can be littered with them without your knowing. In particular, Mac users must check that inadvertent typing of Option-spacebar or Command-spacebar did not introduce one non-breaking-space character for each such keypress.
Remove linebreaks inside paragraphs.
Convert quotation marks and dashes (never a strictly automated process).
You will receive countless MS Word files and PDFs. These are a leading cause of borked Unicode, especially when block quotations from these sources are plunked inside correctly-encoded text.
What goes wrong?
Early MS Word versions – still very much in use in large corporate environments – didn’t use Unicode by default and mis-encode characters. MS Word is engineered to avoid displaying the wrong character, but it remains the wrong character internally and stays wrong when you paste or drag it somewhere else.
PDFs can include nearly any imaginable form of digital object, including visible characters interspersed with invisible characters and sentences with no space characters between words. (In that case a PDF merely displays a break between words even if it doesn’t actually exist.) What you see is not necessarily what you get in PDF.
The following workflow avoids most mis-encodings from Word and PDF.
Do not copy and paste from either of these sources. Don’t drag and drop, either.
You must export as plain text (UTF‑8) in Word and then open the resulting file in your editor.
You also must export as Text (Plain) in Acrobat. Oddly, the Text (Accessible) setting produces worse results. Even this won’t work all the time because PDFs can include text that is hard to export. Open the resulting file in your editor.
Whether you like it or not, you have no real choice but to use Adobe Acrobat for this function, not any other PDF viewer.
WordPress double-prime error. When typing inside the textarea on a WordPress blog with smart quotes turned on, any sequence that ends in a numeral followed by a neutral quotation mark becomes a numeral followed by a double-prime character, ″. This may also happen even if a period or comma sits between the numeral and the end quote. (I long ago reported this bug.)

Solution: Type real quotation marks, or at least always check for the double-prime character and change it.
The quote/emdash combo. Some blogs (the Awl; Gawker) used a nonsensical combination of neutral quotation marks but also em dashes. This practices makes believe that em dashes are easy characters while quotation marks are difficult. Do not follow this pattern.
Newspapers. Online versions of print newspapers, including the New York Times, export what are surely internally correct quotation marks as neutral. Do not follow this pattern.
I believe every publication, including every individual blogger, should specifically invite corrections of typos and copy errors. A lot of sites do that already, but I think it should be universal. And the invitation to submit corrections should specifically mention that readers can report characters that don’t show up properly. In other words, you or your publication should have a stated policy inviting people to report character-encoding errors in the same way they’d report any other copy error.
On the Twitters: @BorkedUnicode.
Almost pointlessly, a Flickr group to which you can upload screenshots.
Can’t figure out what a character is? Copy and paste it, or a string of characters, into Richard Ishida’s String Analyzer, which will return a list of every character and its Unicode name.
The definitive book on Unicode for informed amateurs is Jukka K. Korpela’s Unicode Explained. You really can sit there and read all 600-odd pages (I did); the book explains Unicode as simply as it ever could be explained. Or you can just search the Google Books version for help with tricky cases.
Looking for a searchable online database of Unicode characters? There are several, but Fileformat.info is the one I use.
Joel Spolsky’s classic article “The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets” isn’t so complicated that only hackers can understand it. Hacks will find it informative, too.
Published 2011.11.14 ¶ Updated 2018.07.23